Like in most areas, pattern classification and machine learning have their hypes. In the early 90-s the neural networks awoke and enlarged the community significantly. This was followed by the support vector machine reviving the applicability of kernels. Then, from the turn of the century the combining of classifiers became popular, with significant fruits like adaboost and random forest. Now we have neural networks again and deep learning.
Due to the hypes interest shifts to new areas before the old ones are fully exploited. Here we will take a breath and return to adaboost and compare it with similar but less complex alternatives.
Adaboost is a great, beautiful system for incremental learning. It generates simple base classifiers, see [1]. Classifiers found later in the process are trained by subsets of the data that appear to be difficult to classify correctly. Every base classifier receives directly a classifier weight based on its success in performing its local task. Finally all base classifiers are combined by a weighted voting scheme based on these weights.
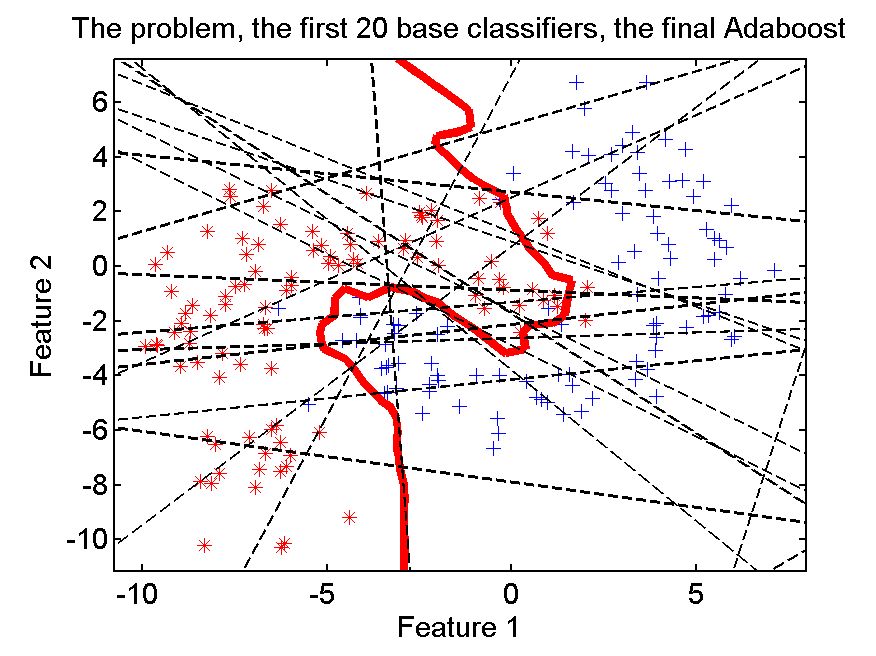
The base classifiers should be simple, so called weak classifiers. They are expected to show some performance, but also have a large variability. In the above example we used linear perceptrons (a single neural network neuron), randomly initialized and trained shortly. In the left scatter plot the first 20 are shown for one of the training sessions.
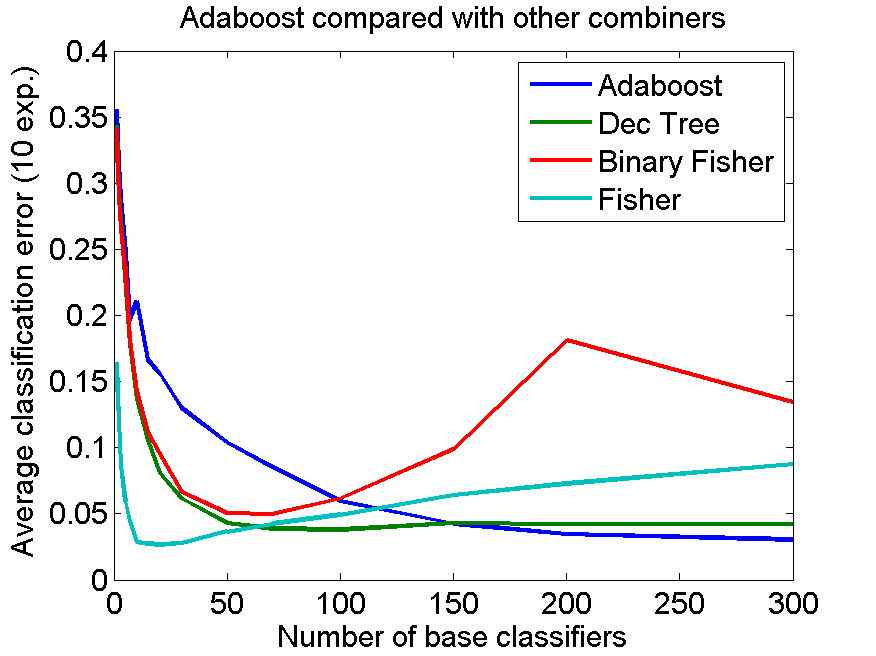
The blue line in the right plot shows the averaged adaboost performance (over 10 experiments) as a function of the number of base classifiers until 300. It is monotonically decreasing due to the clever choice in the adaboost algorithm to estimate classifier weights individually and not to optimize them in their relation to each other.
Is the adaboost combiner really the best one? Let us study three alternatives. They are computed for every collection generated in the adaboost procedure First, the decision tree. It starts with finding the best classifier for the entire training set and then gradually splits it according to the classifier decisions. If a pure node is reached (a cell in the feature space with training objects of a single class) a final decision is made. For an increasing number of base classifiers this system may overtrain. This is protected by pruning the decision tree. The dark green line in the right plot shows that this is not entirely successful. The results are best for about 100 base classifiers and are slightly worse than the final adaboost result. For small numbers of base classifiers, however, the decision tree is significantly better than the adaboost combiner.
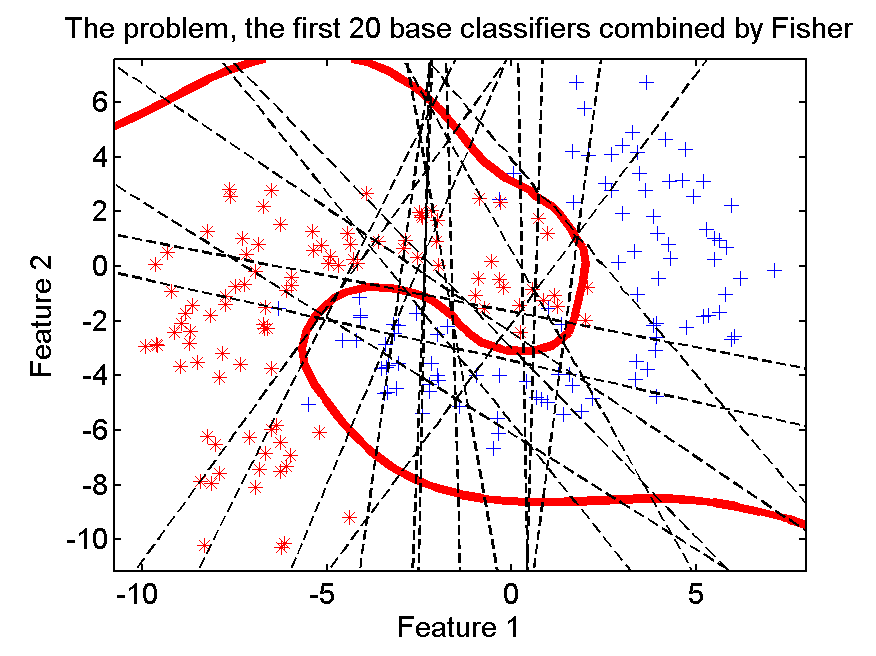
The fisher classifier optimizes the combination of the weights of the base classifiers for the training set. Again this is done for each considered set separately. The number of weights to be optimized increases, resulting in overtraining. This is maximum (red line) if the number of weights equals the size of the training set, a well known phenomenon. For this number of objects the optimization is maximum sensitive to noise [3]. For small numbers of base classifiers the performance is similar to that of the decision tree.
The above mentioned fisher procedure (red line) is called here binary fisher as it is based on just the binary (0-1) outcomes of the base classifiers. There is, however, more information, the distance to the classifier. It can be used as an input for the fisher procedure instead. This results in the green line in the plot. It is especially good for very small numbers of base classifiers. In this example it is even slightly better than the final adaboost result, 0.027 against 0.031.
The advantage of this fisher combiner over the adaboost combiner is that its best performance is based on just 20 base classifiers instead of 300. What it combines are still the base classifiers generated in the adaboost scheme.Is this really significant or can other, more simple procedures be used as well? We tried another scheme.
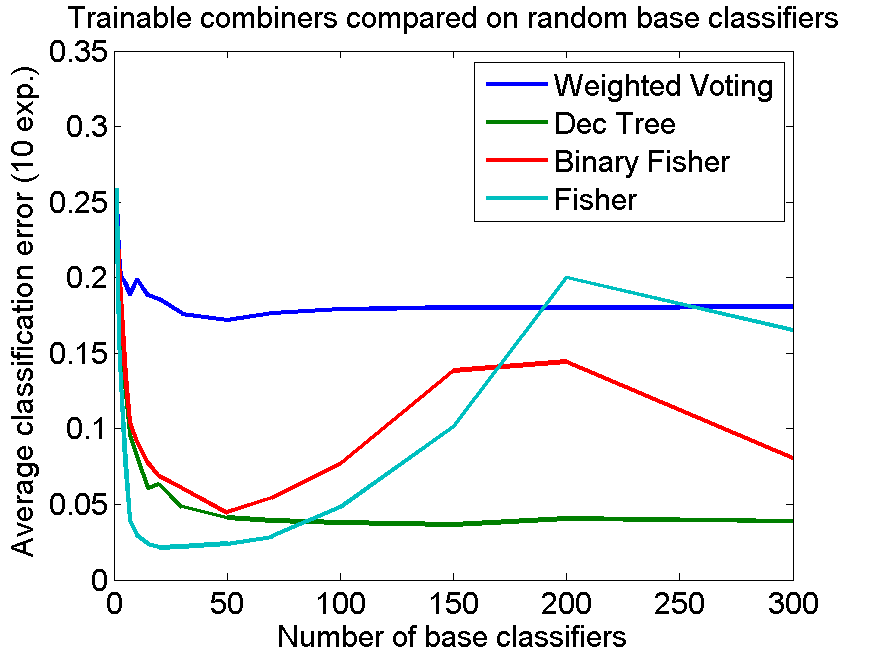 Instead of generating weak classifiers according to the adaboost scheme, in which the resulting classifiers are dependent, we generated a set of independent classifiers by using the 1-nearest neighbor classifier based on just two randomly selected objects, one from each class. Using the weighted voting combiner [2] a set of weights can be found very similar to adaboost, but now based on the entire training set in which each object is equally important. The blue line in the right plot shows that this procedure is much worse than adaboost. The decision tree and the fisher combiners, however, show similar results as in the first experiment. For small numbers of base classifiers the results are even significantly better, 0.021 for the fisher combiner . This suggests that the adaboost scheme of generating base classifiers is good for the adaboost combiner, but not for other combiners.
Instead of generating weak classifiers according to the adaboost scheme, in which the resulting classifiers are dependent, we generated a set of independent classifiers by using the 1-nearest neighbor classifier based on just two randomly selected objects, one from each class. Using the weighted voting combiner [2] a set of weights can be found very similar to adaboost, but now based on the entire training set in which each object is equally important. The blue line in the right plot shows that this procedure is much worse than adaboost. The decision tree and the fisher combiners, however, show similar results as in the first experiment. For small numbers of base classifiers the results are even significantly better, 0.021 for the fisher combiner . This suggests that the adaboost scheme of generating base classifiers is good for the adaboost combiner, but not for other combiners.
As a result we have a much more simple classifier than adaboost, similar in its architecture of a weighted combination of base classifiers. It has in this example a similar performance. A larger set of experiments should judge the value of the random fisher combiner as presented here.
The source of the experiments as well as an implementation of the random fisher combiner, both based on PRTools, are available.
[1] J. Friedman, T. Hastie , R. Tibshiran, Special Invited Paper. Additive Logistic Regression: A Statistical View of Boosting, The Annals of Statistics, 28(2), pp. 337-374, 2000.
[2] L.I. Kuncheva and J. J. Rodriguez, A weighted voting framework for classifiers ensembles, Knowledge and Information Systems 38, 2014, 259-275
[3] R.P.W. Duin, Classifiers in Almost Empty Spaces, Proc. ICPR15, vol. 2, 2000, 1-7.

Filed under: Classification